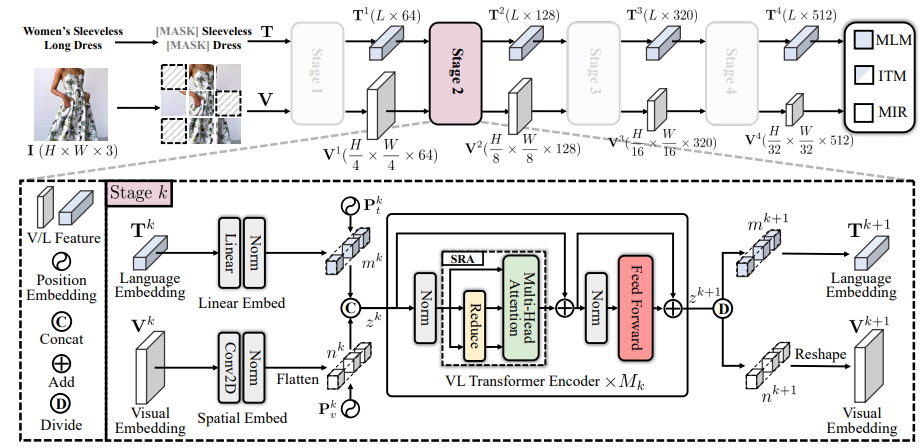
We present a masked vision-language transformer (MVLT) for fashion-specific multi-modal representation. Technically, we simply utilize the vision transformer architecture for replacing the bidirectional encoder representations from Transformers (BERT) in the pre-training model, making MVLT the first end-to-end framework for the fashion domain. Besides, we designed masked image reconstruction (MIR) for a fine-grained understanding of fashion. MVLT is an extensible and convenient architecture that admits raw multi-modal inputs without extra pre-processing models (e.g., ResNet), implicitly modeling the vision-language alignments. More importantly, MVLT can easily generalize to various matching and generative tasks. Experimental results show obvious improvements in retrieval (rank@5: 17%) and recognition (accuracy: 3%) tasks over the Fashion-Gen 2018 winner, Kaleido-BERT.
If you use our work, please cite our publication.
@article{ji2023masked,
author = {Ji, Ge-Peng and Zhuge, Mingchen and Gao, Dehong and Fan, Deng-Ping and Sakaridis, Christos and Gool, Luc Van},
title = {Masked vision-language transformer in fashion},
journal = {Machine Intelligence Research},
pages = {1--14},
year = {2023},
publisher = {Springer}
}

